
At long last, you’ve made it to the data collection stage of your survey project. It’s time to warm up the automated data collection equipment, make sure everything is programmed correctly and prepare for the results to come in.
As with each stage of survey administration, there is some prep work needed to ensure accurate outcomes. In the case of automated data collection, it all begins with the Data Schema.
A Data Schema is a blueprint of what all the numbers mean in the data file you will get with your results (see chart below). The good news is that you get to design this to your liking.
You will assign a value to each response (i.e, “1 = Daily”; “2 = Several times a week,” etc). We recommend you Include values for “blank” and “multi marks,” as shown in the chart below as -9 and -8, respectively. You will also want to include ranges where applicable. For example, if you are surveying teenagers and asking the year they were born, you can put a range on the year that you are expecting. If a date comes up out of range, the automation will stop for an operator to confirm the entry and ensure there was not a substitution error.
As part of your data schema, we highly recommend you include a data dictionary (see 3rd column in chart below). This identifies all the expected values for that question.
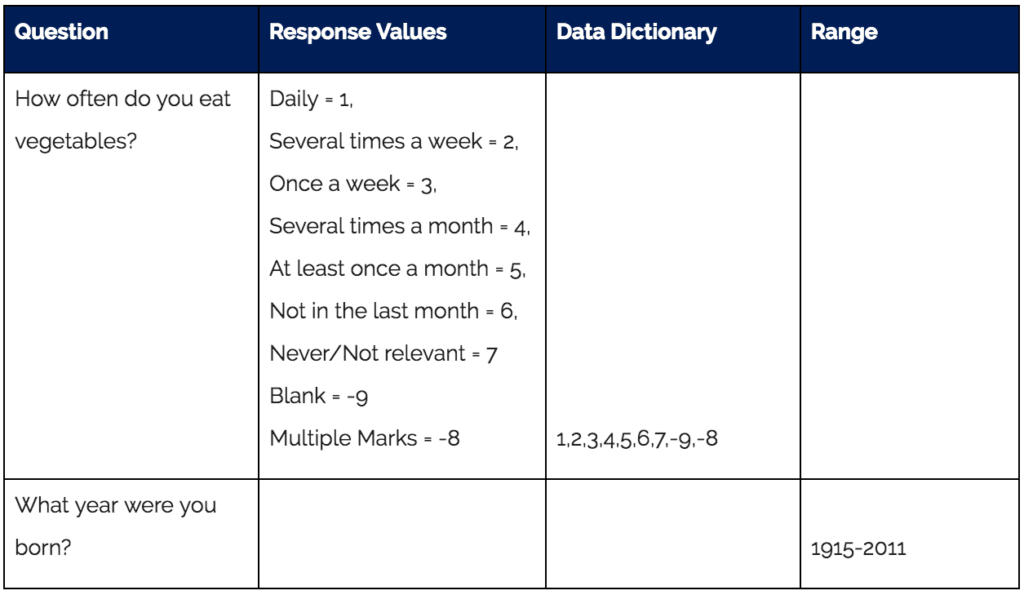
The data dictionary column allows you to easily build a query to check for values that are out of range.
Sample Data Testing
After your survey is programmed, the testing begins. Programmatic testing against the data schema ensures that your multi-modal data collection will run seamlessly and that the resulting data is delivered in a format you can use. Your data collection partner will specifically test for:
-
- Coding – Did it code correctly?
-
- Exporting – Did it export correctly?
-
- Formatting – Can the customer work with the data as supplied or do they need something changed or adjusted
We start with a test that accounts for all possible survey responses. (The total number of surveys filled out is equal to the maximum number of response choices on the survey, plus 2). To test this, we fill out one survey with all the first response choices marked. Then we fill out a second survey with all the second response choices, etc. We follow this up with a test to account for multiple marks entered on single response items, another with test text entered for comment style questions, and finally, one for “mark all that apply” questions. By testing for all possible response types, we ensure that all questions are programmed correctly.
The next test involves data sampling (i.e, using a small subset of your respondent population to collect data). We do a mixed response test with live forms filled out by a respondent subset to ensure nothing unexpected occurs in the way respondents are filling out the forms. For example, we might see that many people are selecting multiple responses to a single response question. This gives us the opportunity to alter the programming to capture all responses.
The Data Schema is an essential part of data collection programming, testing and processing. By creating an impeccable blueprint and investing the time to properly test samples, you will ensure the integrity of your results and safeguard against the pain of data loss!
For more information on data schemas, data collection or any aspect of survey mail management, contact us today!